Changelog
Tracing, Agent Evaluation, Python SDK, and richer prompts
This release introduces full LLM tracing, end-to-end agent evaluation, an official Python SDK, train/test split, multi-variable prompt support, chat message prompt templates, and configurable structured output evaluation.
Tracing
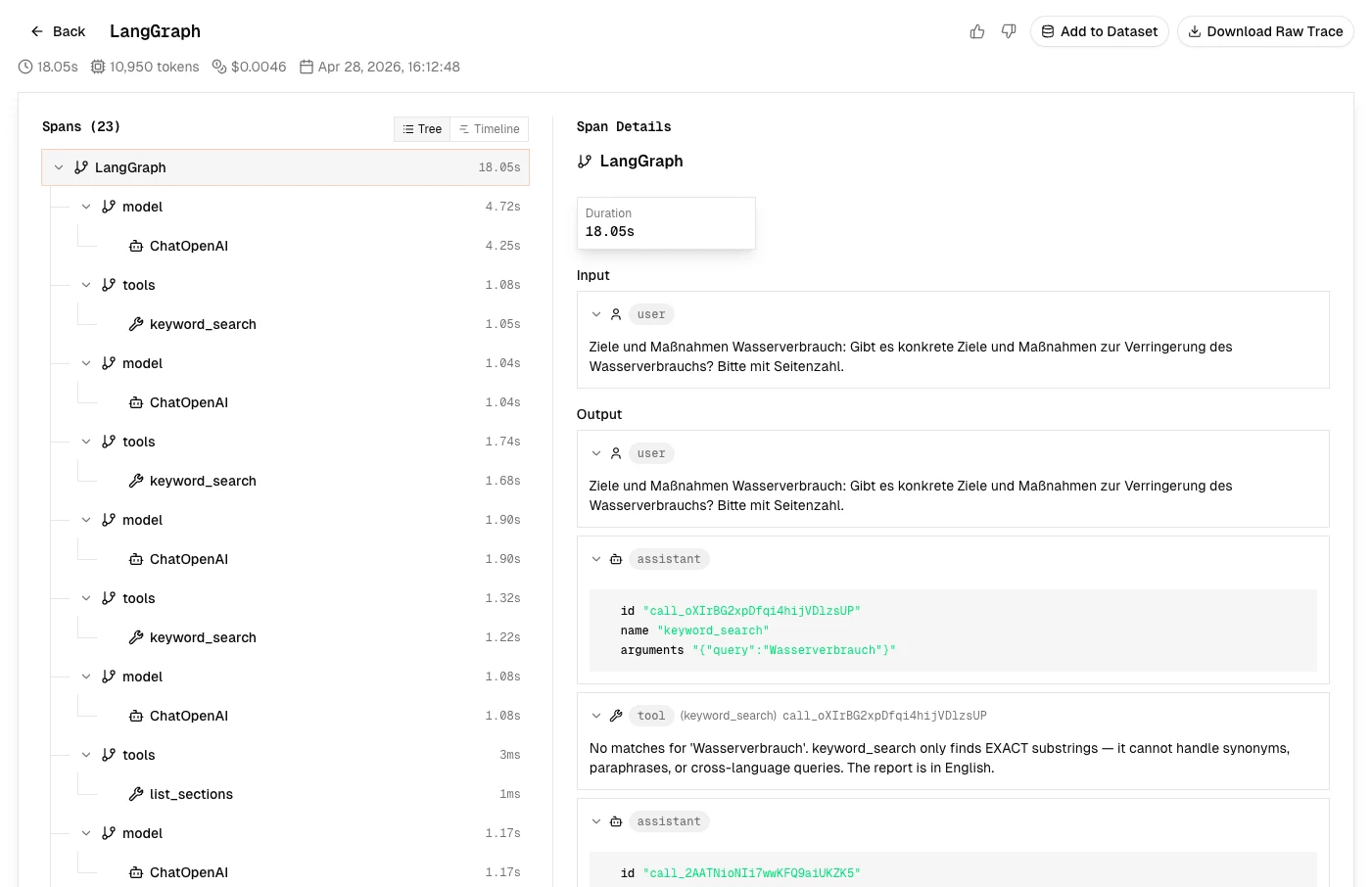
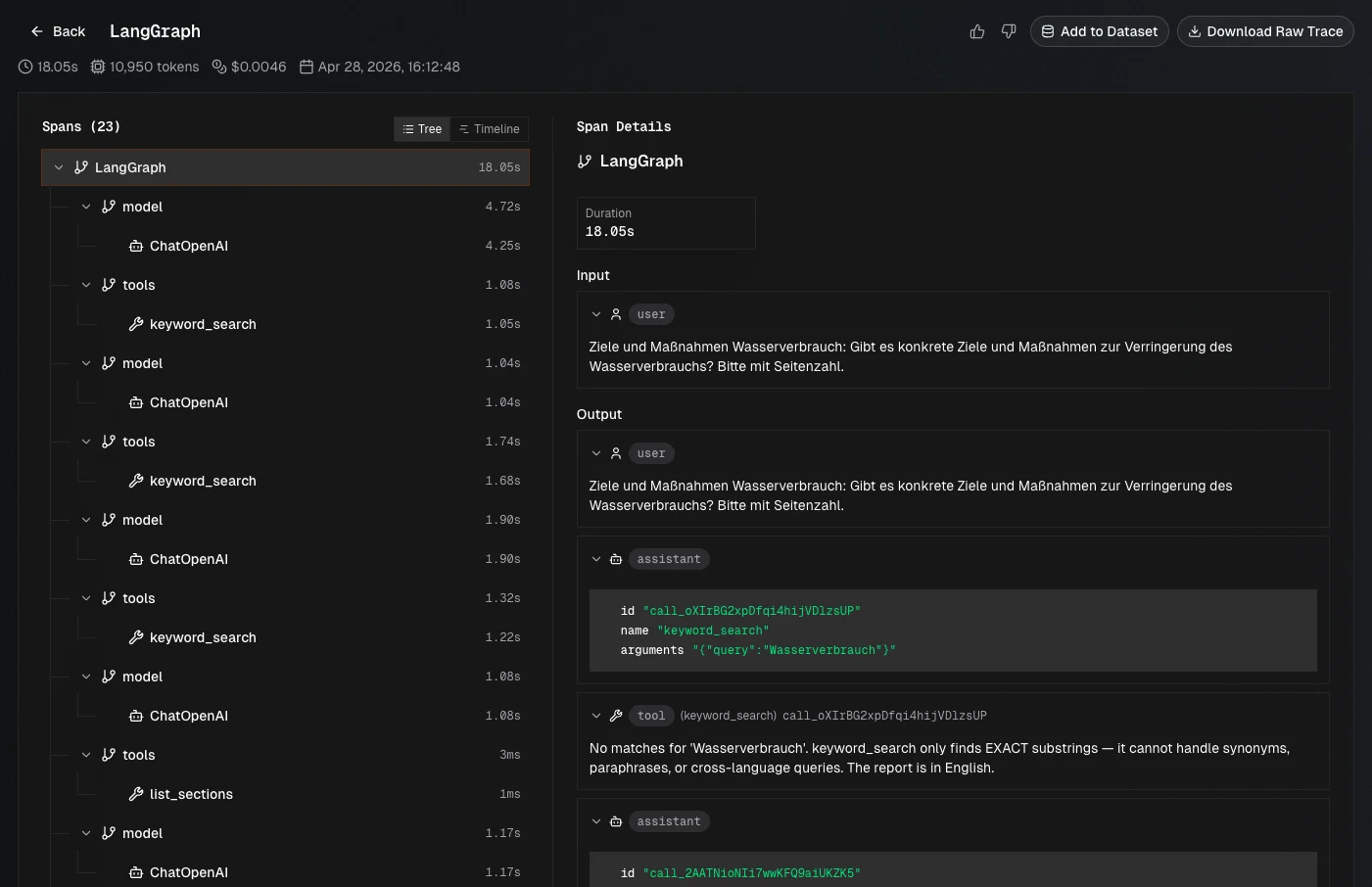
Promptic now provides automatic, OpenTelemetry-based observability for every LLM call your application makes. See request and response payloads, token counts, cost, and latency across OpenAI, Anthropic, Google, LangChain, and Cohere — without changing your application code.
- Drop-in instrumentation via
promptic_sdk.init() - Provider-agnostic span schema for cross-vendor comparison
- Full trace history powering Agent Evaluation and prompt optimization downstream
See the Tracing guide to get started.
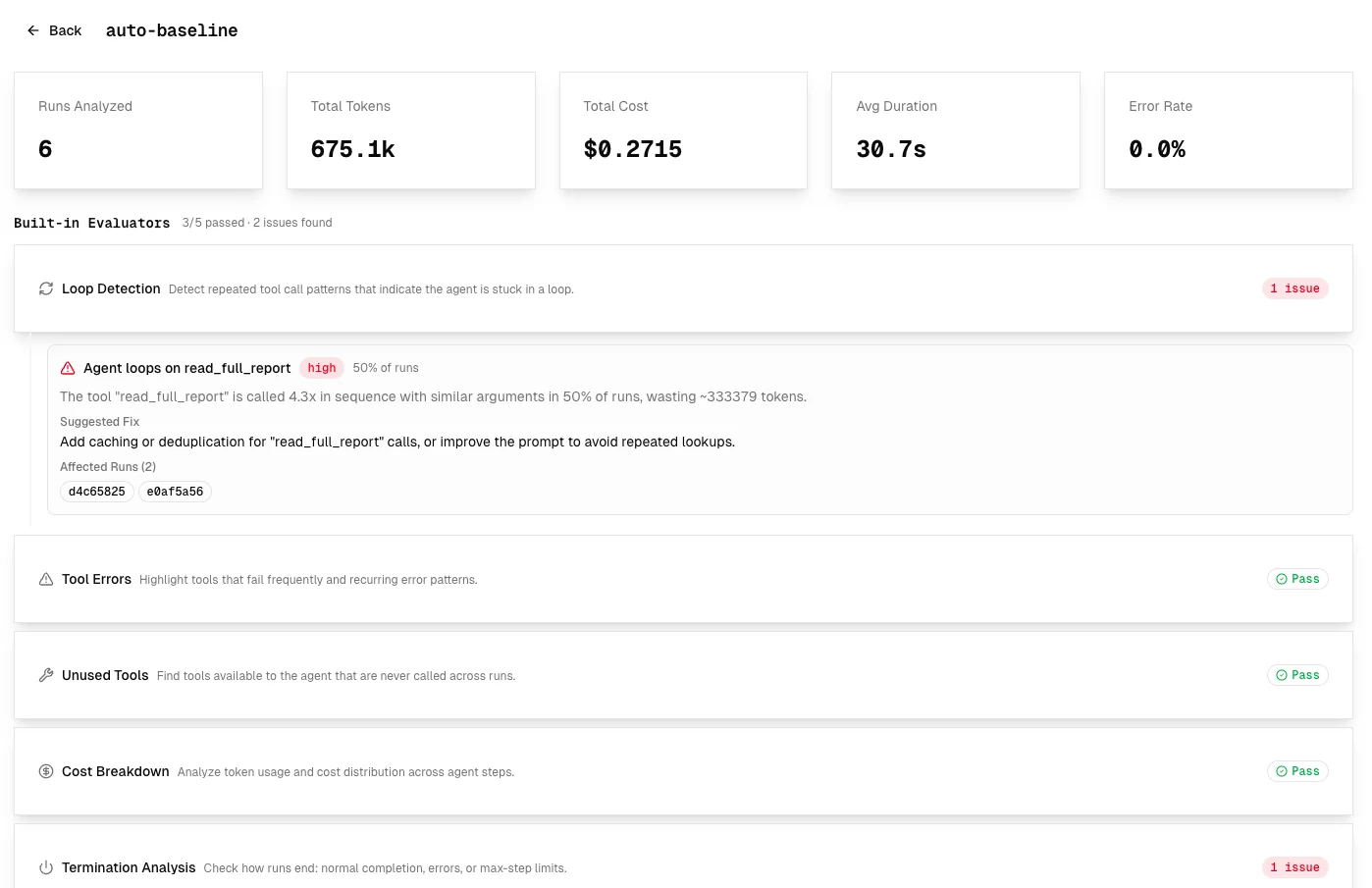
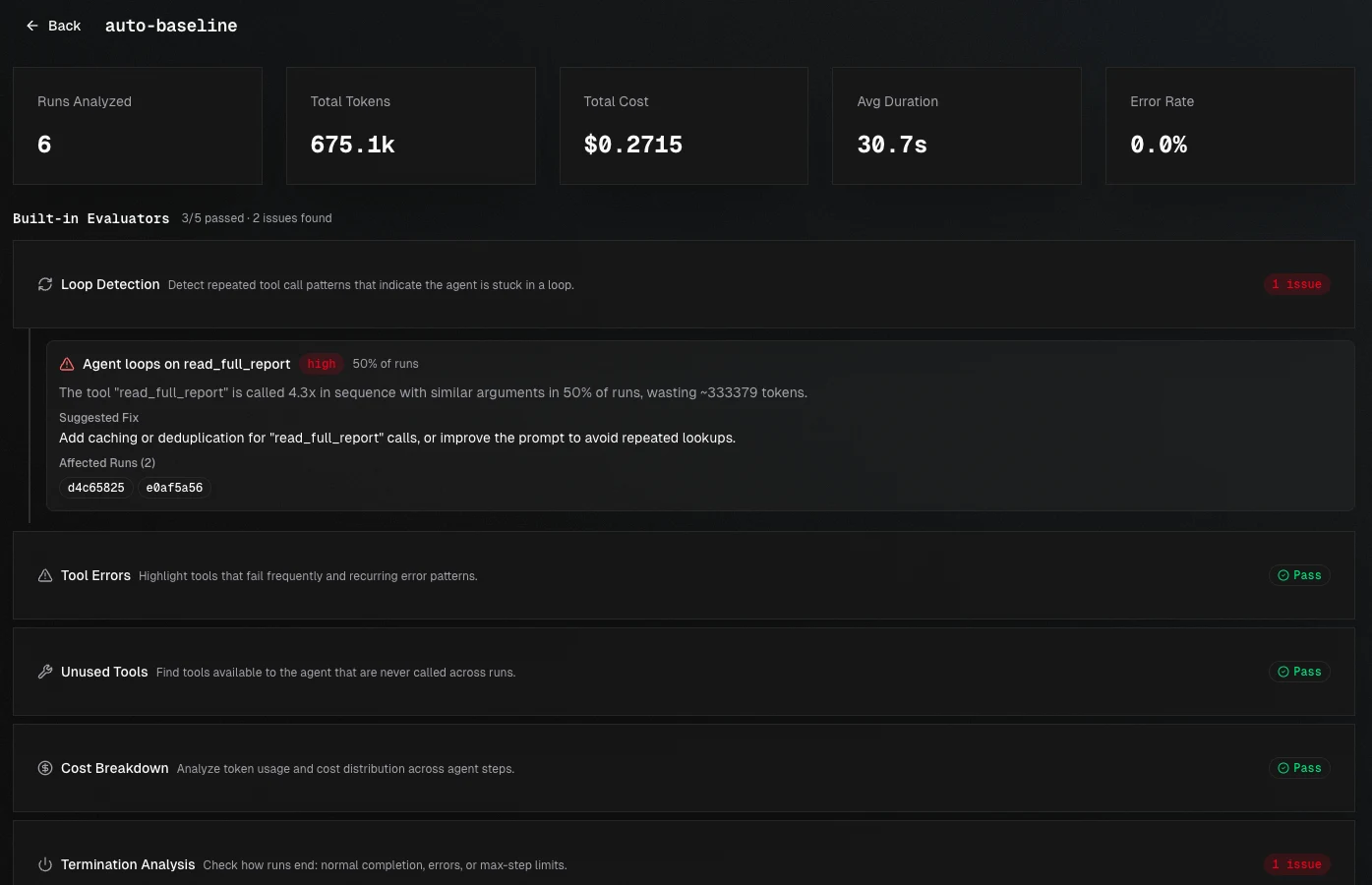
Agent Evaluation
Score multi-step agent runs end-to-end. Tag traces with dataset and run parameters, trigger an evaluation, and get AI-generated insights on quality, errors, and regressions — without writing custom evaluators.
See the Agent Evaluation guide for the full setup.
Python SDK
The official promptic_sdk package brings tracing, dataset tagging, and prompt optimization to Python applications, with first-class support for OpenAI, Anthropic, Google, LangChain, and Cohere.
- Auto-instrumented OpenTelemetry tracing
- Programmatic experiment management
- CLI for local workflows
import promptic_sdk
from openai import OpenAI
promptic_sdk.init(api_key="...")
client = OpenAI()
client.chat.completions.create(
model="gpt-4.1-mini",
messages=[{"role": "user", "content": "Hello"}],
) # automatically tracedSee the SDK installation guide and the Python SDK reference.
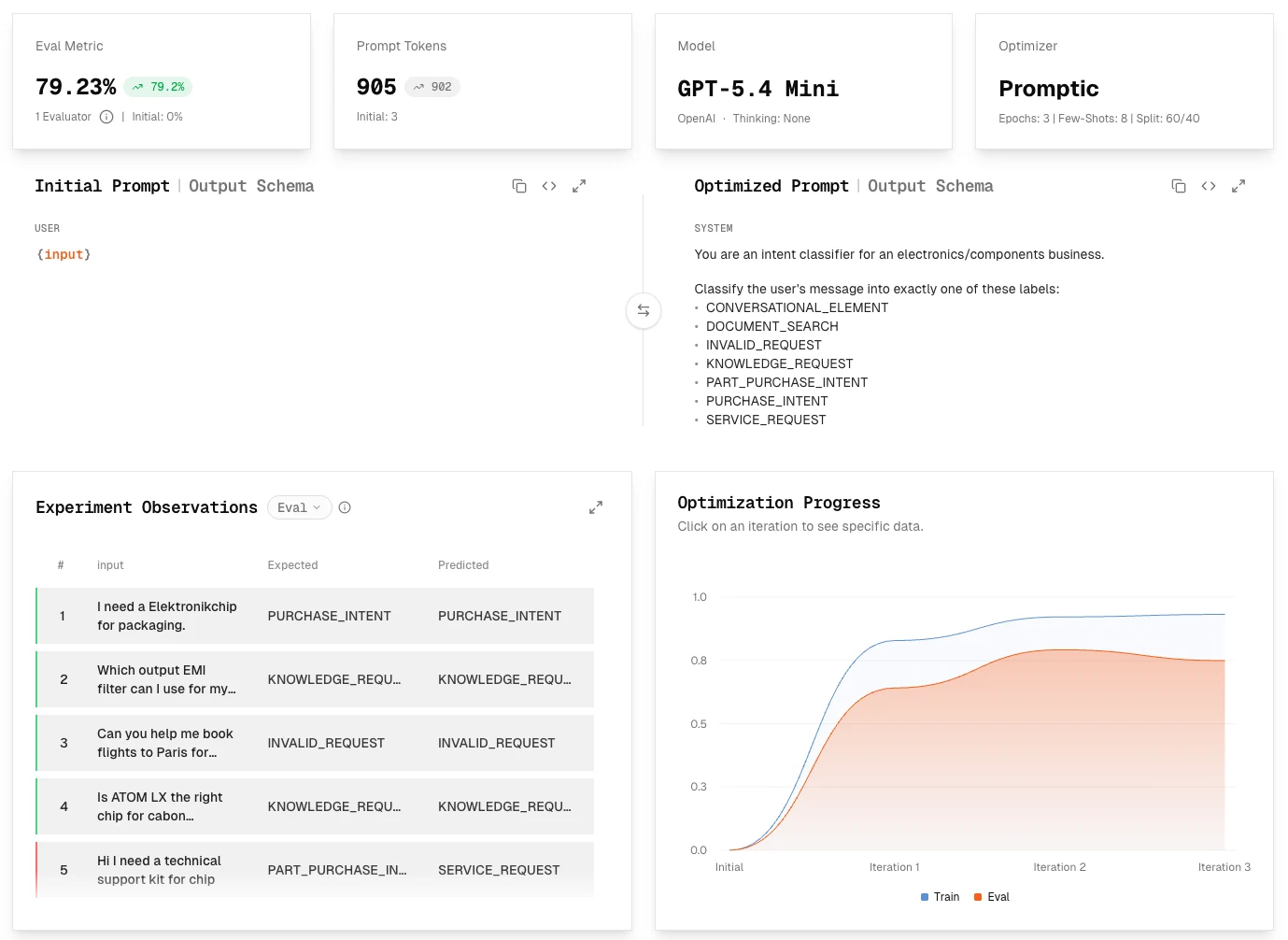
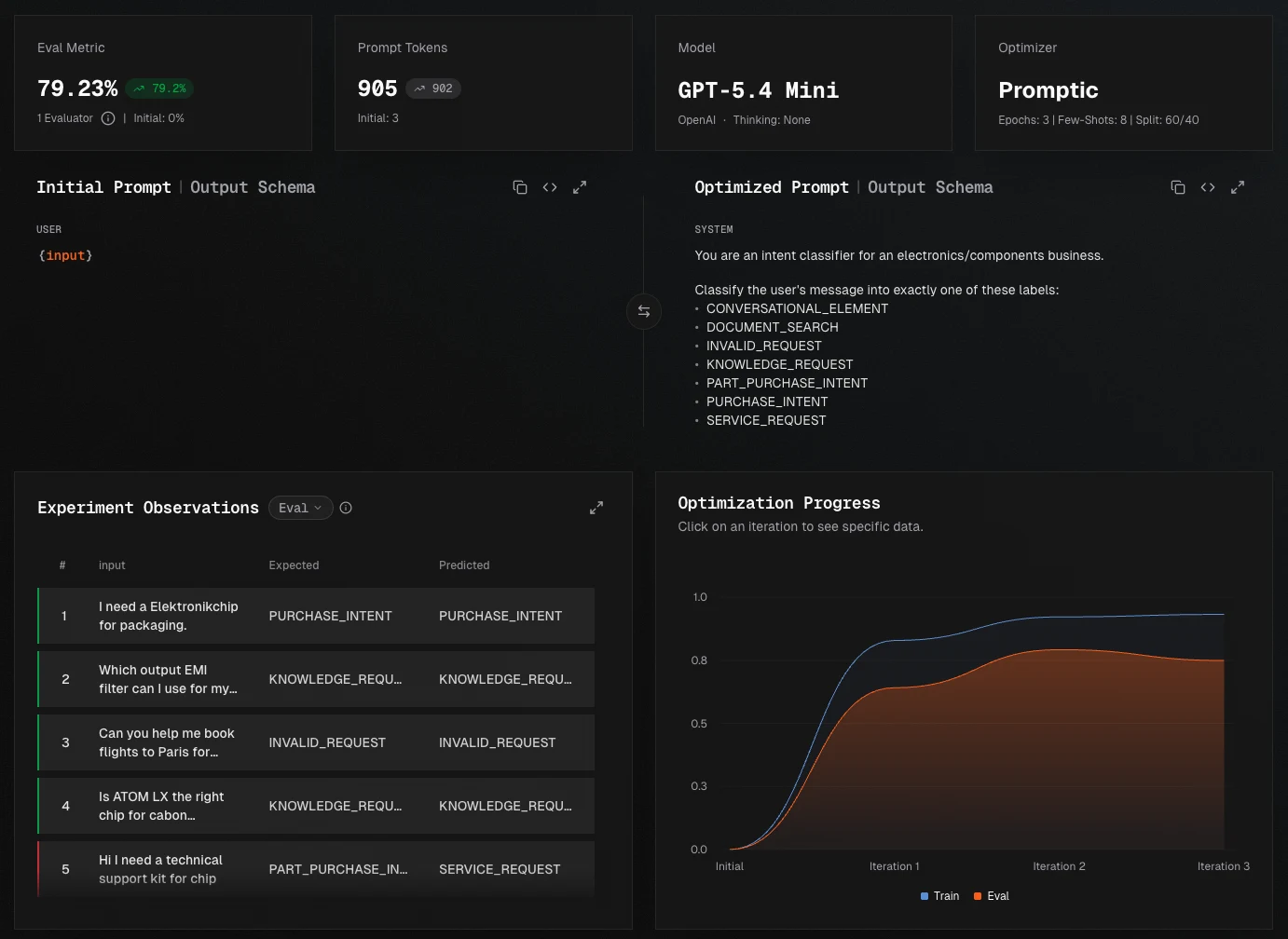
Train / test split
You can now split your dataset into a training set used for optimization and a held-out evaluation set used for unbiased scoring — preventing optimizers from overfitting to the same observations they're being graded on.
- Configure a
train_split_ratioper experiment (e.g.0.8reserves 20% for evaluation) - Split is deterministic per experiment, so reruns score against the same held-out set
- Available in both the experiment UI and the Python SDK / optimizer hyperparameters
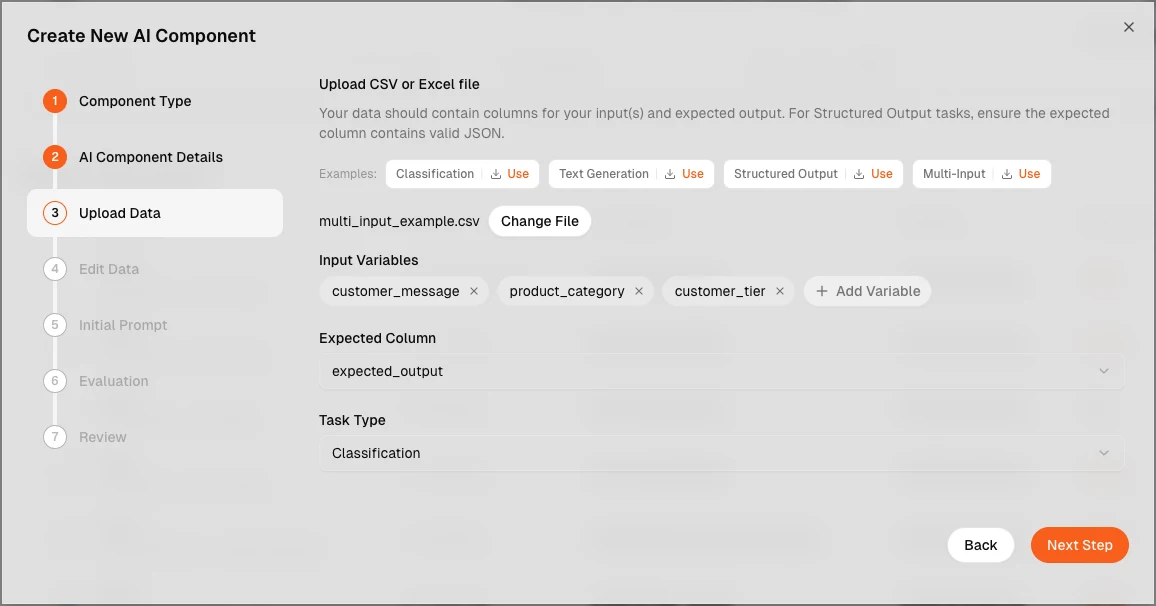
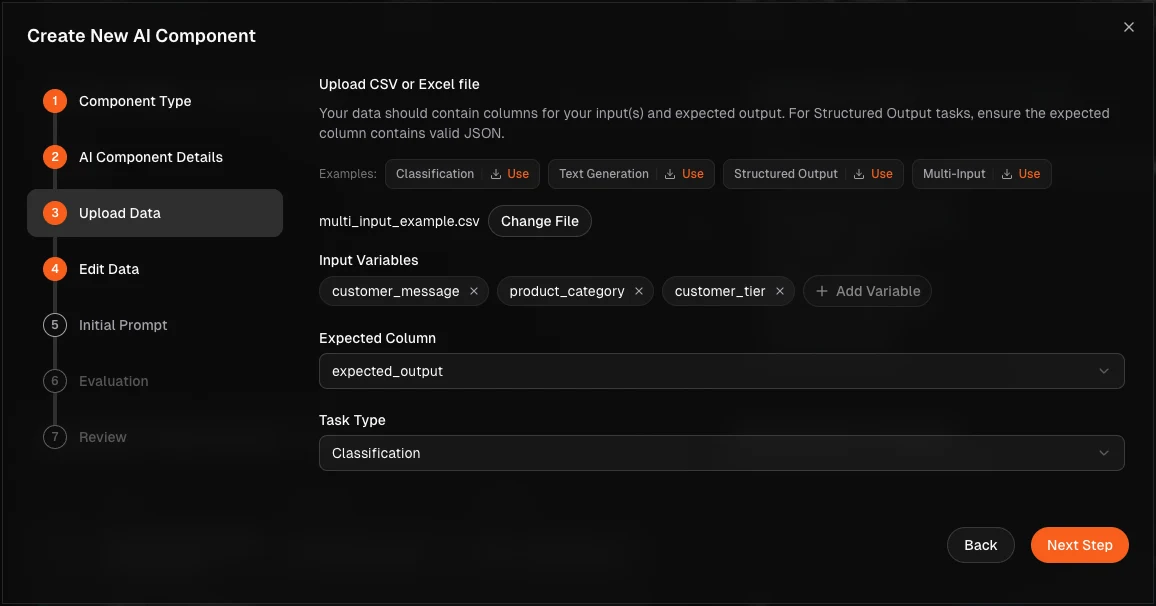
Multi-variable prompt support
Define and optimize prompts that take more than one input — useful for RAG, multi-turn flows, and structured tasks where context, query, and instructions are passed as separate fields. Variables flow through optimization, evaluation, and predictions consistently and work with all evaluator types.
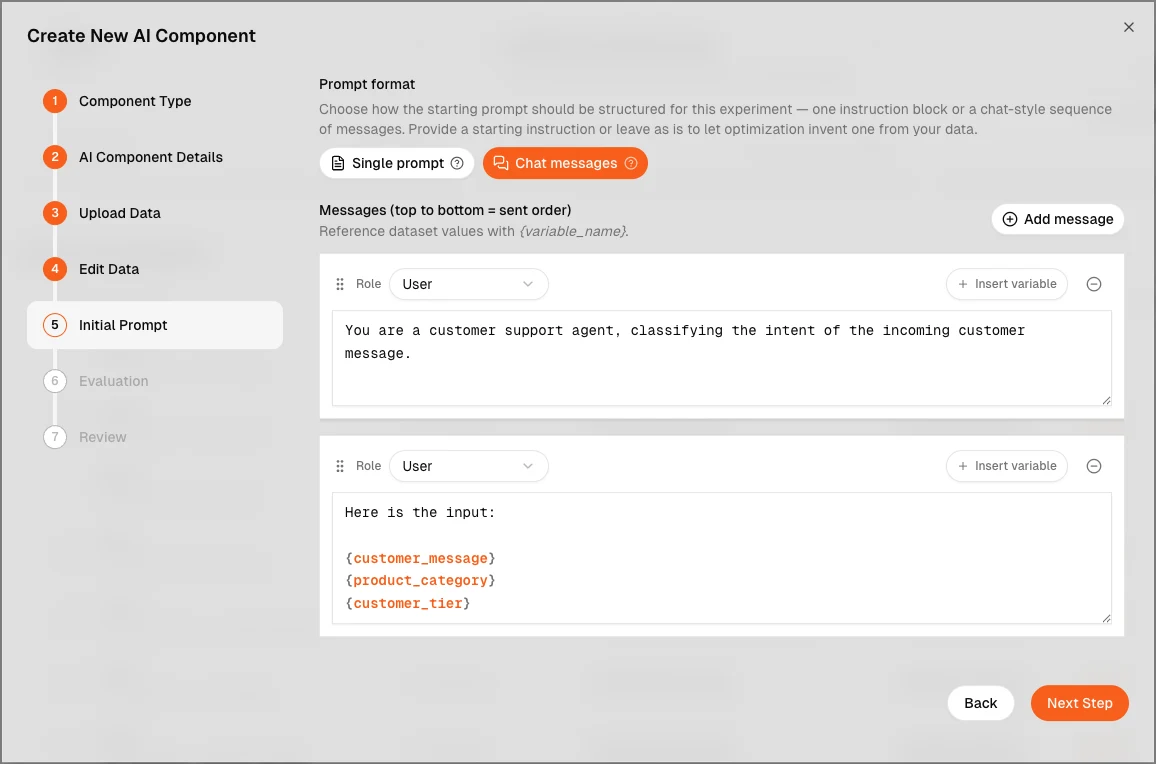
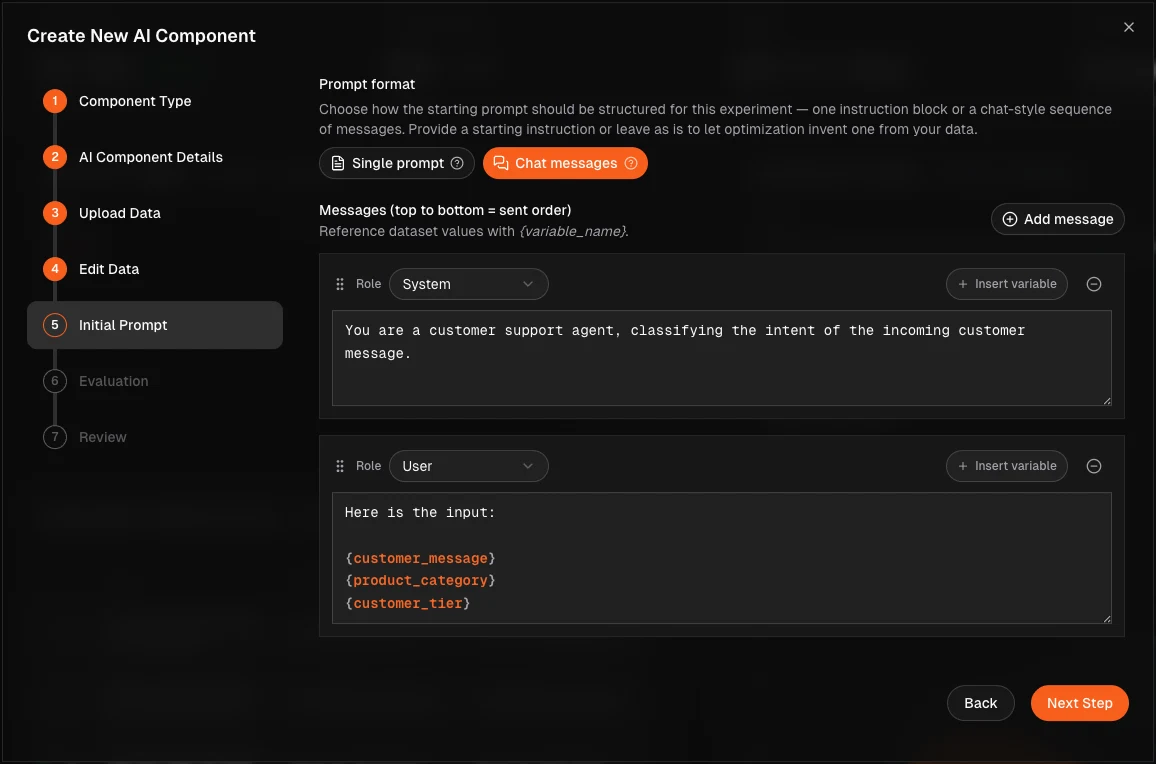
Chat message prompt support
In addition to plain-text prompts, Promptic now optimizes structured chat messages — system, user, and assistant turns — so the format you optimize matches the format you ship. Per-turn variable interpolation is supported, with round-trip compatibility across providers that use the messages API.
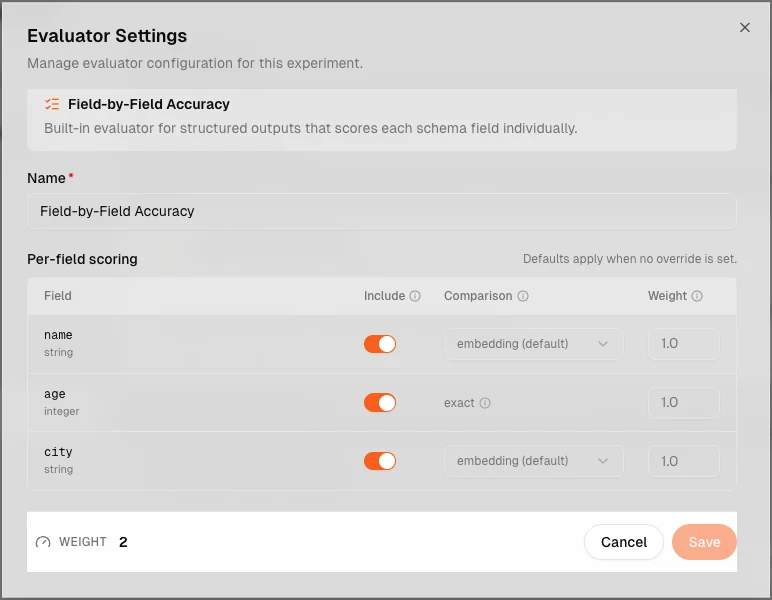
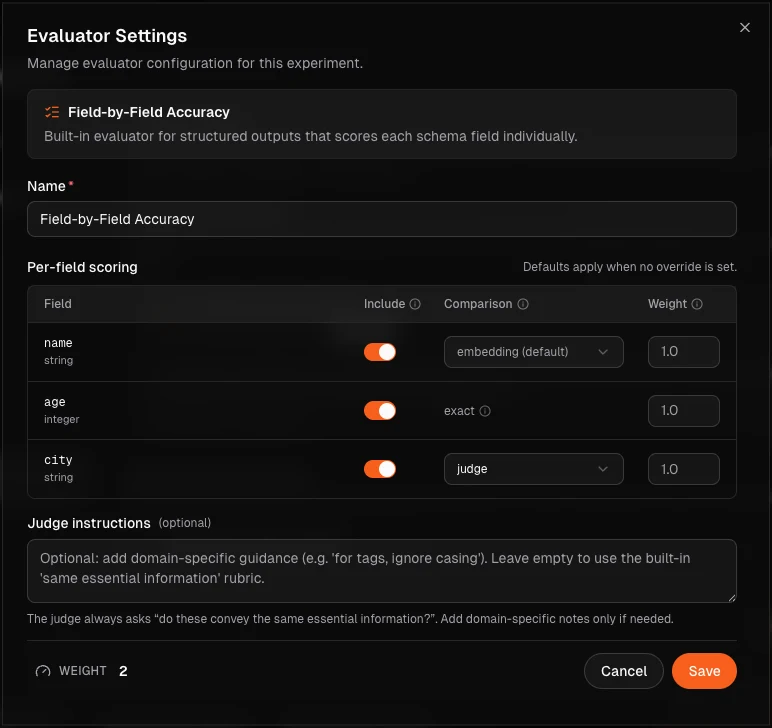
Configurable structured output evaluation
Structured-output experiments can now be evaluated on only the fields that actually matter, with different matching strategies per field and judge configuration tuned to each field's role. Optional or noisy fields no longer drag down the score, and regressions are debuggable field-by-field instead of via a single aggregate number.
- Per-field
include,weight, andrequiredhonored by the scoring aggregation - Per-field strategy overrides (
FieldStrategyfor scalars,ArrayStrategyfor lists, plus the newContainsStrategy) - Configurable LLM judge with three judge types, per-field prompts, and a cosine-similarity floor for fast filtering
- Per-field scoring diagnostics surfaced in the experiment view